- A sudden jump in duplicate rows due to a faulty join
- A decrease in a data source due to an upstream error
- A system failure caused no new records to be inserted
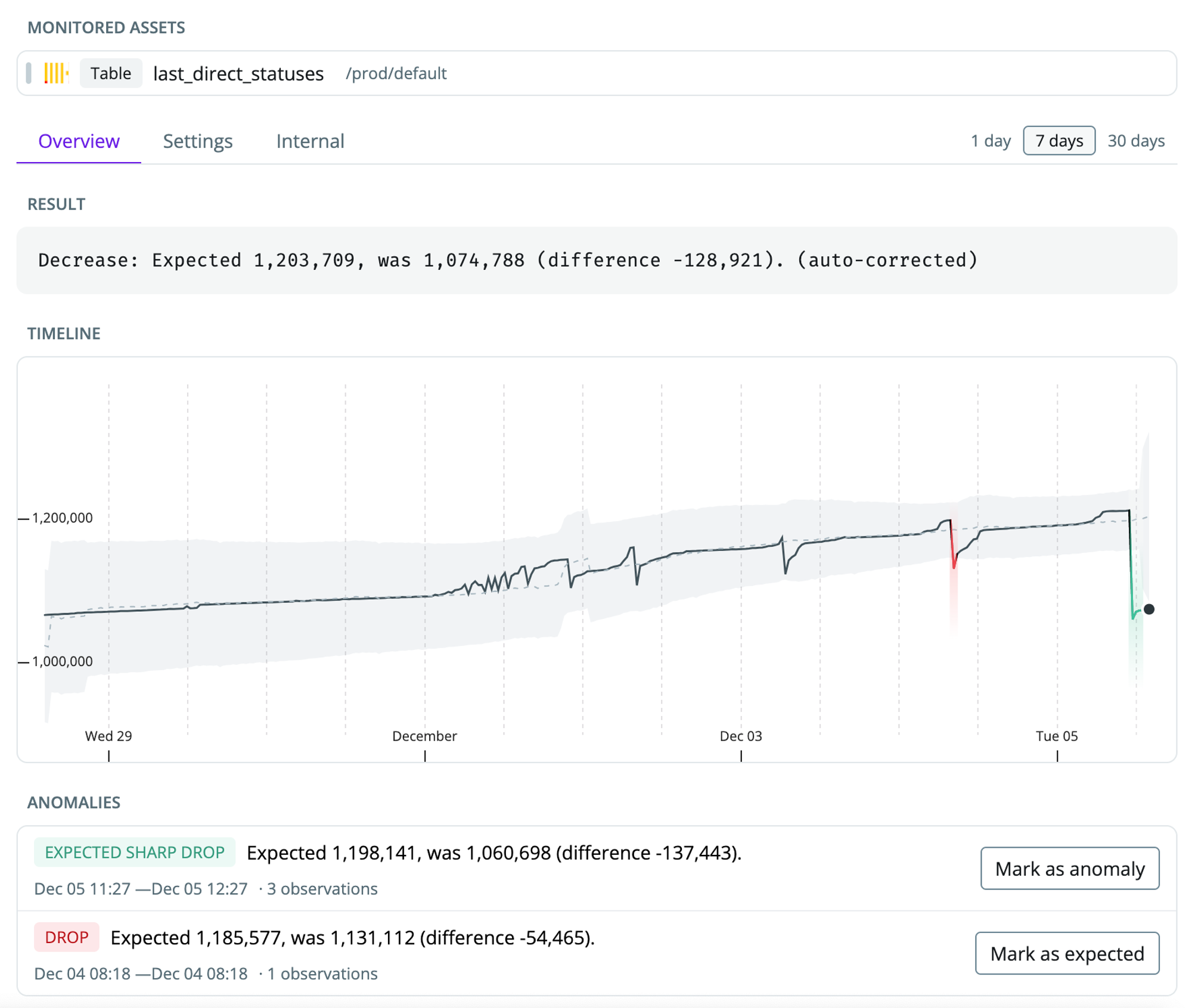
Default volume monitor
The default freshness and volume monitors have been merged into the Table stats monitor. You can see more on the Table stats monitor page.
row_count from the Snowflake table information schema. As the monitor queries the information schema, you only incur minimal additional costs even when they are run frequently. The monitor works out of the box, which makes it easy to deploy at scale.
Unless you need custom functionality, such as grouping by a different time field, we recommend you use default volume monitors.
Default volume monitors are run every 60 minutes.
Setting up a default volume monitor
- Navigate to
Health→Manage monitors - Click
Create monitor groupto define the tables you want to monitor - Use the browser to narrow down the tables you want to monitor
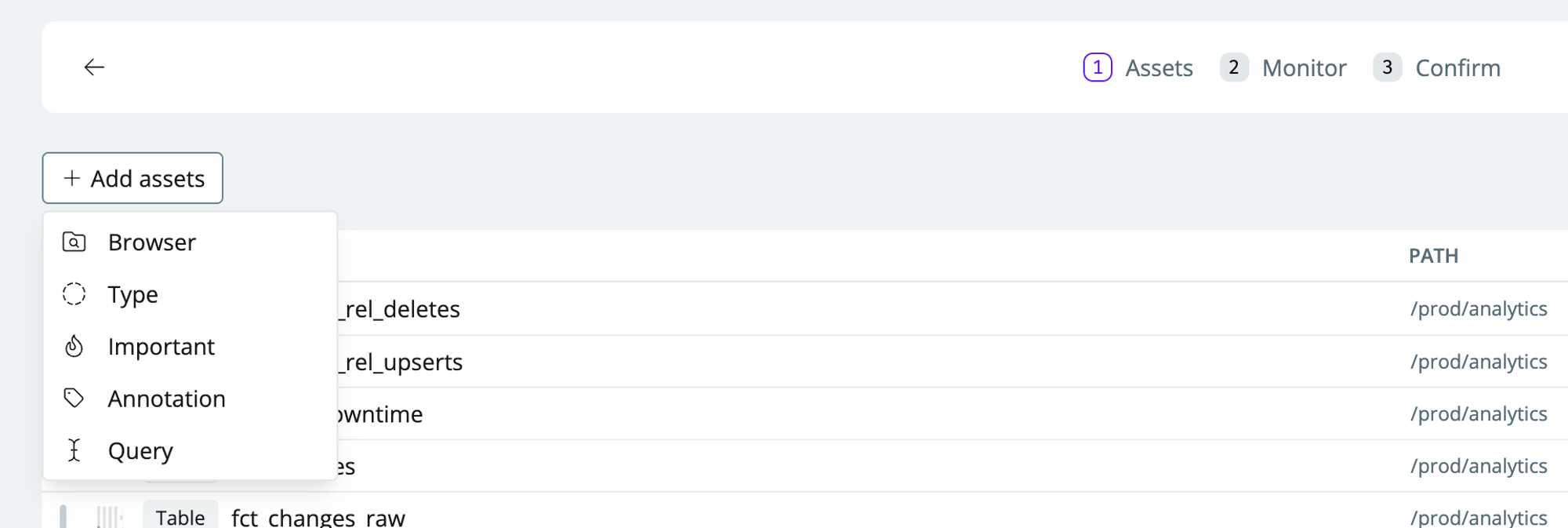
- Browser—select specific schemas or search for tables to monitor (your data warehouse tables and transformation models from dbt, SQLMesh, and Coalesce Transform are automatically mapped)
- Annotation—select assets with metadata definitions such as tags defined in your transformation layer (dbt, SQLMesh, or Coalesce Transform)
- Important—select assets that you’ve marked as important
- Query—advanced selection. E.g., search for specific keyword matches
-
Check
Volumeto set up a volume monitor group
-
Name the monitor (e.g., important tables volume monitor).
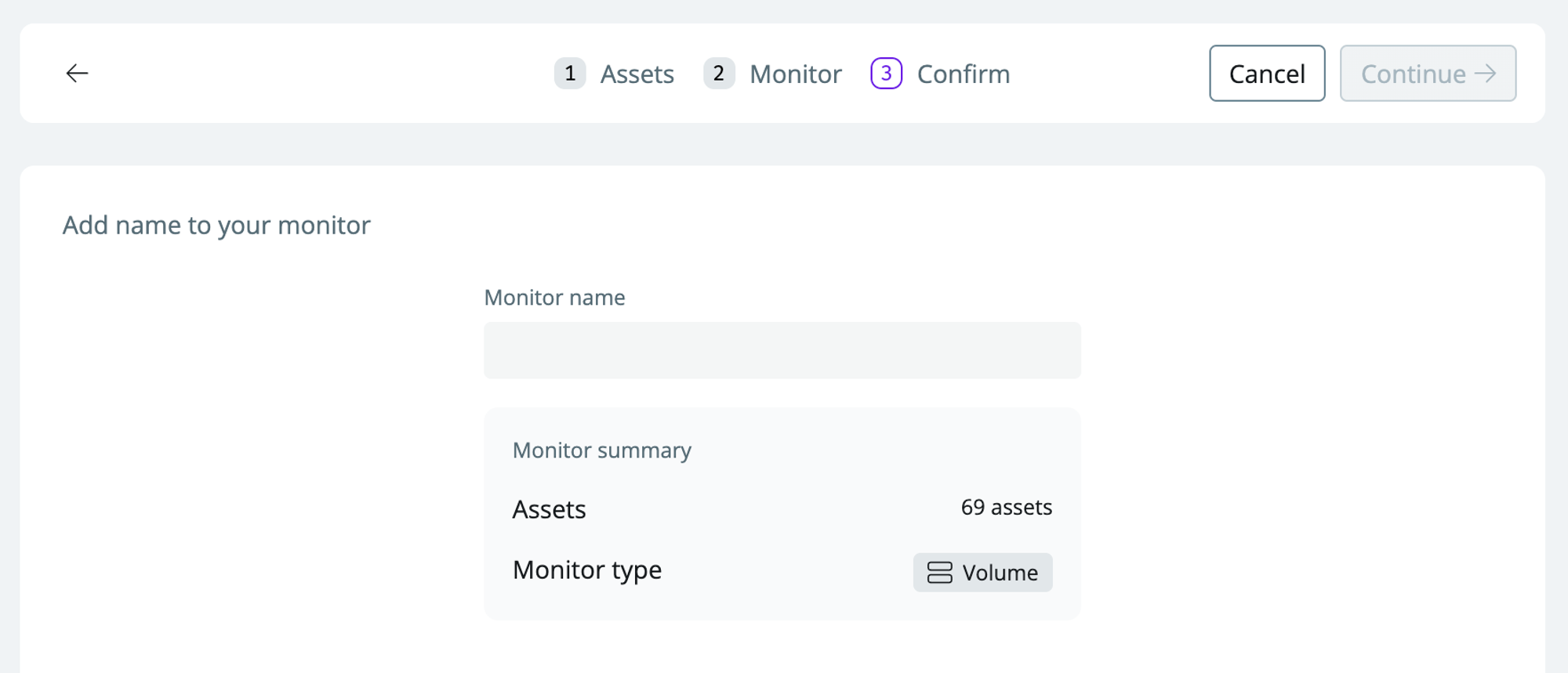
-
Click
continueto set up the monitor
As soon as you’ve set the monitor up, it will start learning the behaviors of your data every hour. You should expect ~10 days before the monitor has built an understanding of the seasonality and patterns in your data and is confidently able to detect anomalies
Custom volume monitor
Unlike the default volume monitor, the custom volume monitor queries your raw data. This gives you more configuration options, such as specifying a time dimension or automatically grouping by a segment. However, it also means that each monitor must be configured individually and that you may incur additional costs from running it.Custom volume monitors are designed as growth monitors meaning that they look at the growth or shrink in the data relative to the previous period as specified by the time partition. This makes them suitable for detecting subtle changes or if no new data starts arriving, even for a short period.
Setting up a custom volume monitor
-
Navigate to the table or transformation model (dbt model, SQLMesh model, Coalesce node) where you want to set up the monitor and click
Add Monitor
-
Select
Volumeto start creating a custom volume monitor
-
Configure the monitor with the relevant settings
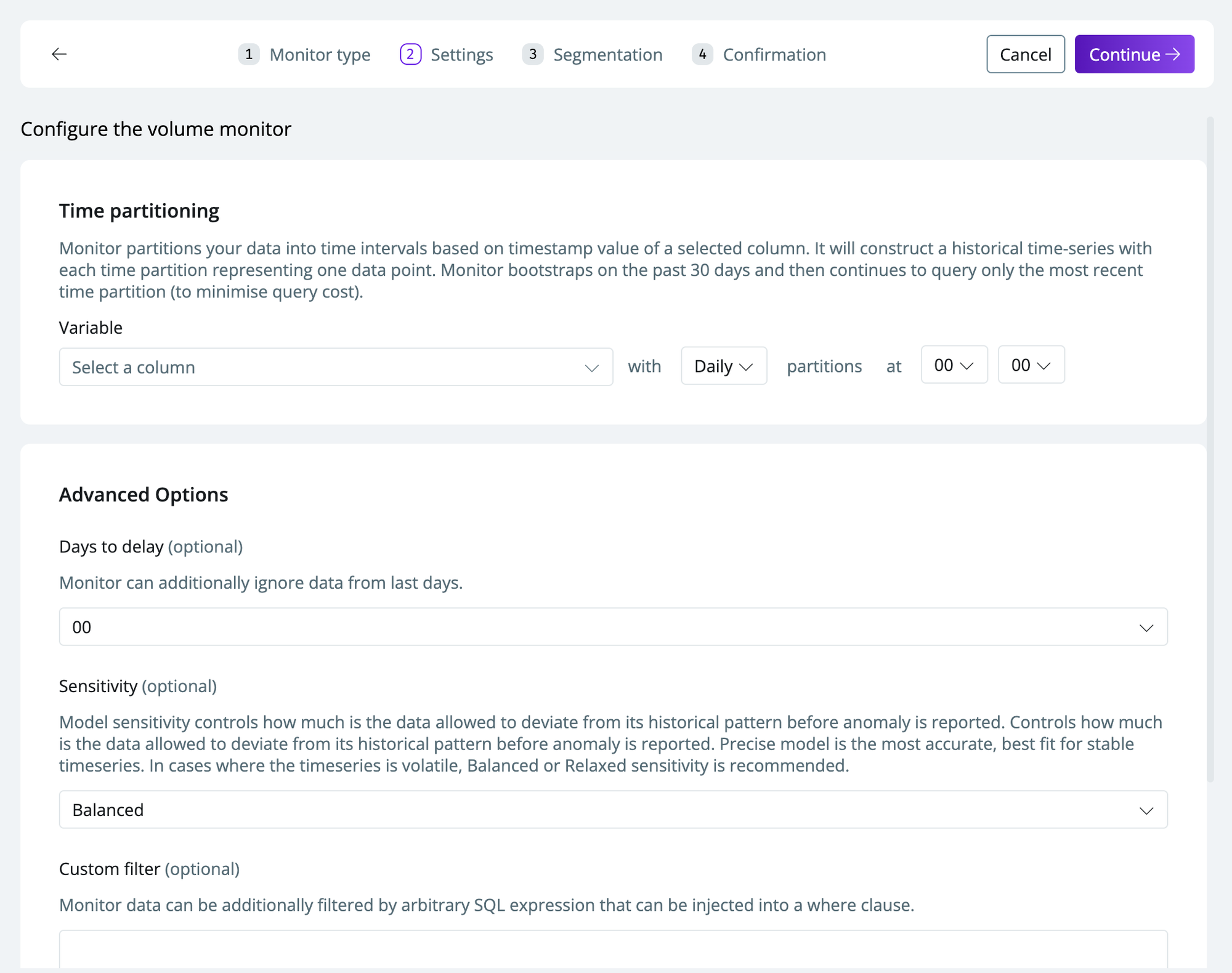
- Time partition—the time partition you want your data segmented by (e.g., creation_date)
- Days to delay—days to ignore if you have a delay in when you expect fresh data
- Sensitivity—see Configuring model sensitivity
- Custom filter—specify custom SQL to filter by
-
Select a
variableto segment by (optional). This will create multiple time series for each segment you select to include- If you only want to create a monitor for specific segments, toggle
Selected valuesand select the desired values - If you select
All values, new values are automatically added.
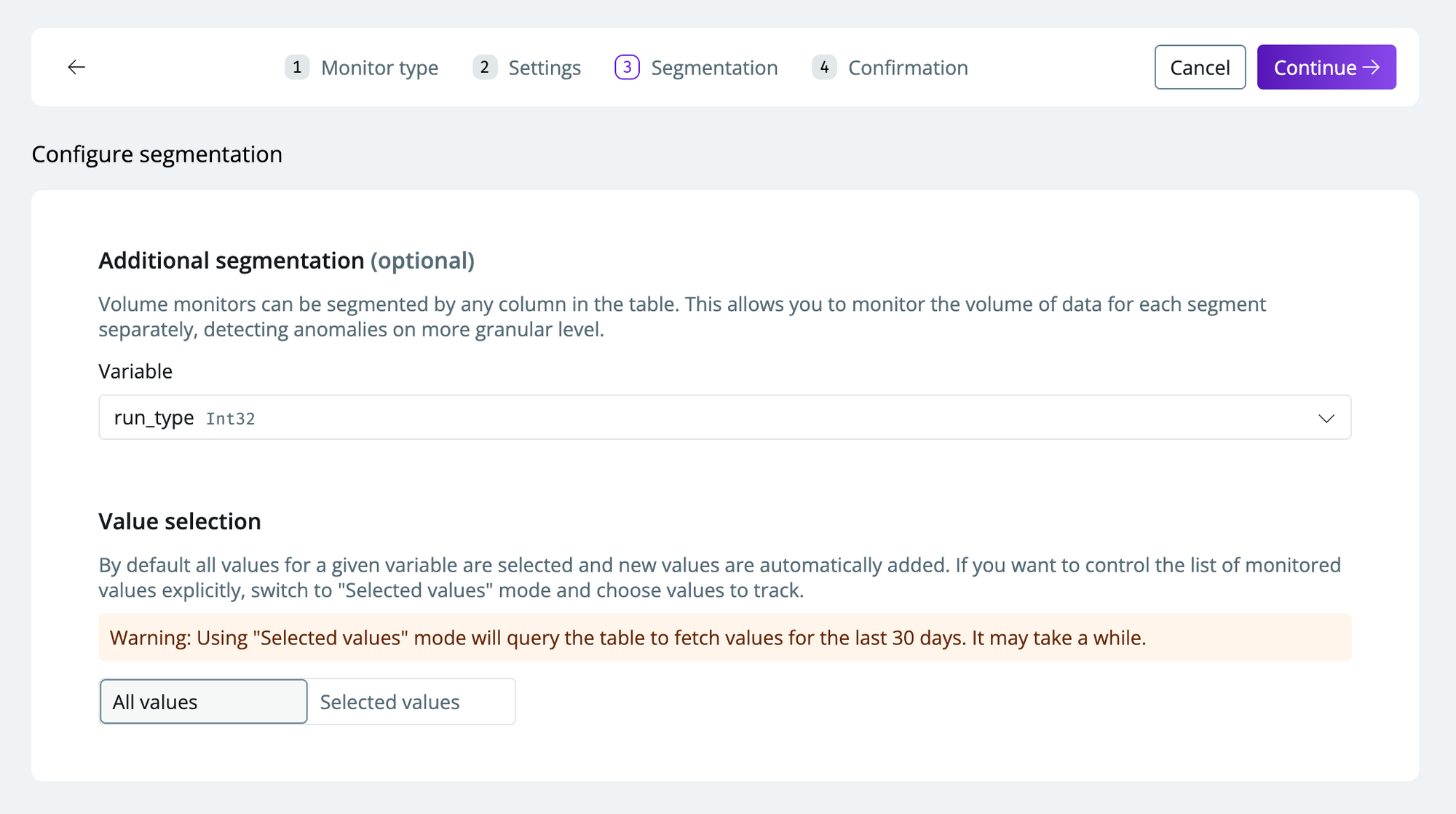
- If you only want to create a monitor for specific segments, toggle
-
Click
continueto set up the monitor with the specified configurations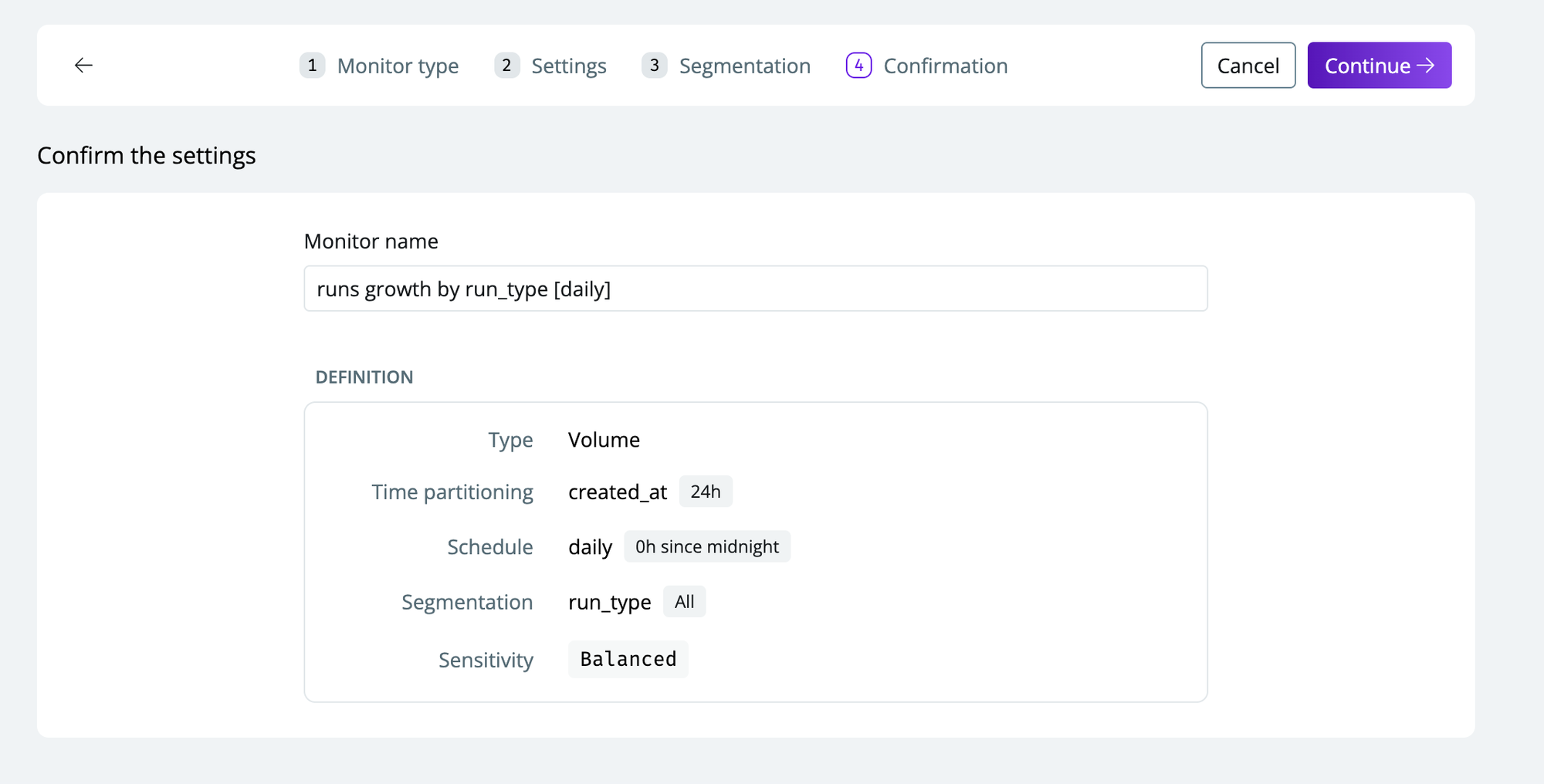
Custom monitors partition your data into time intervals based on the timestamp value of a selected column. It will construct a historical time series, each time partition representing one data point. Monitor bootstraps on the past 30 days and then continue to query only the most recent time partition (to minimize query cost). This means that the monitor will be able to detect anomalies right after you’ve set it up