- Sudden spikes in null or empty values after a pipeline change
- Drops in the number of unique IDs, indicating upstream duplication issues
- Unusual shifts in a numeric metric such as fare amount, order value, lead time, etc.
- Outliers in mean, max, or standard deviation that may indicate data corruption
Metrics tracked automatically
Each selected field will automatically generate a time-series for the following metrics (depending on data type):| Metric | Description |
|---|---|
| Number of rows | Total number of rows in the dataset |
| Number of null | Count of null values |
| Percentage of Null | Percentage of null values |
| Number of empty | Count of empty string values |
| Percentage of Empty | Percentage of empty string values |
| Number of unique | Count of unique values |
| Percentage of Unique | Percentage of unique values relative to total rows |
| Mean | Average value of the field |
| Median | Median value |
| Min | Minimum value |
| Max | Maximum value |
| Standard deviation | Statistical standard deviation |
Setting up a field stats monitor
-
Navigate to the table where you want to create the monitor and click
Add Monitor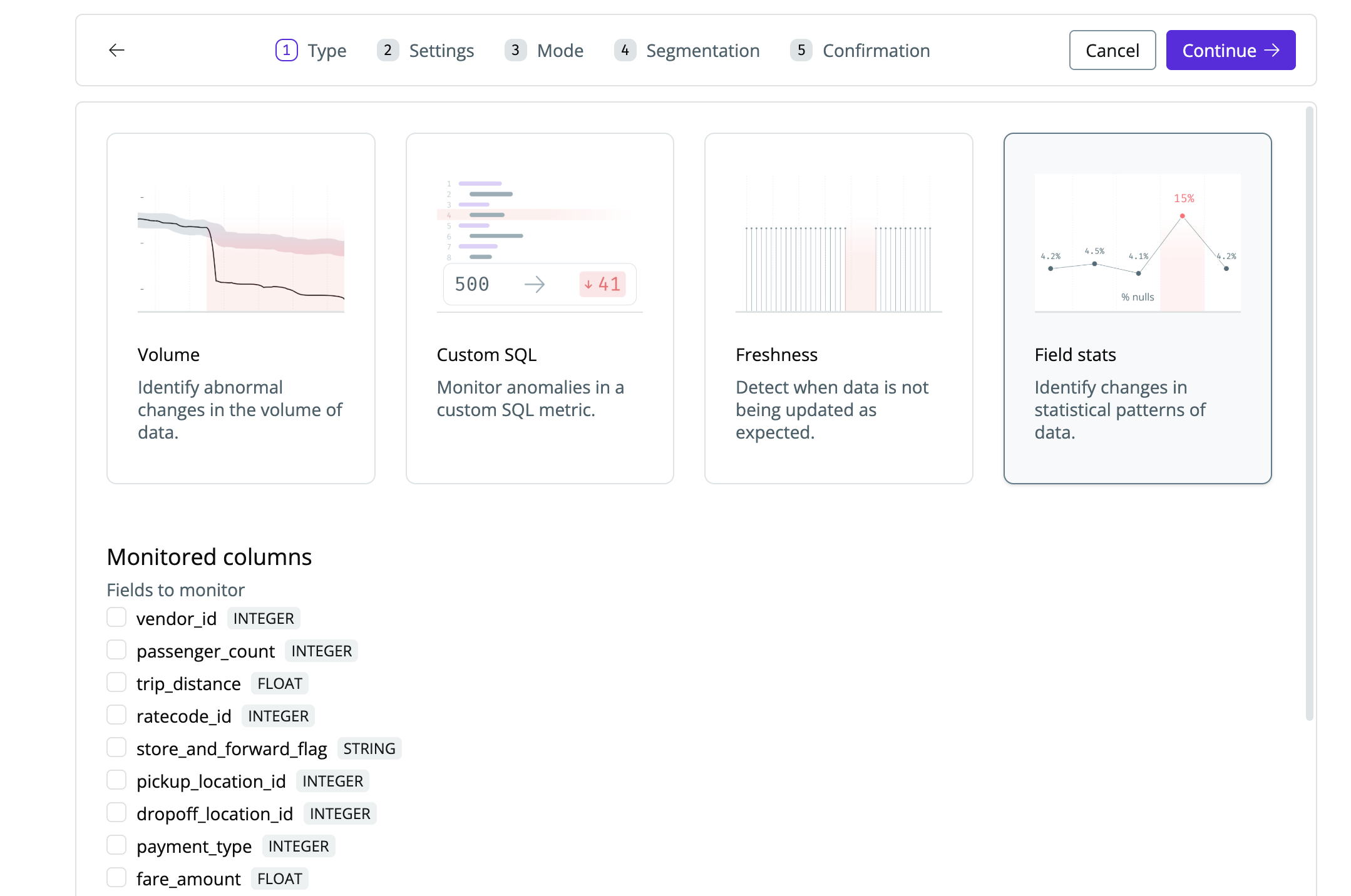
-
Select
Field statsand choose the fields you want to monitor
You can monitor one or multiple fields at once. -
Configure time partitioning. A time-series will be learned per metric per field, using the timestamp column you select.
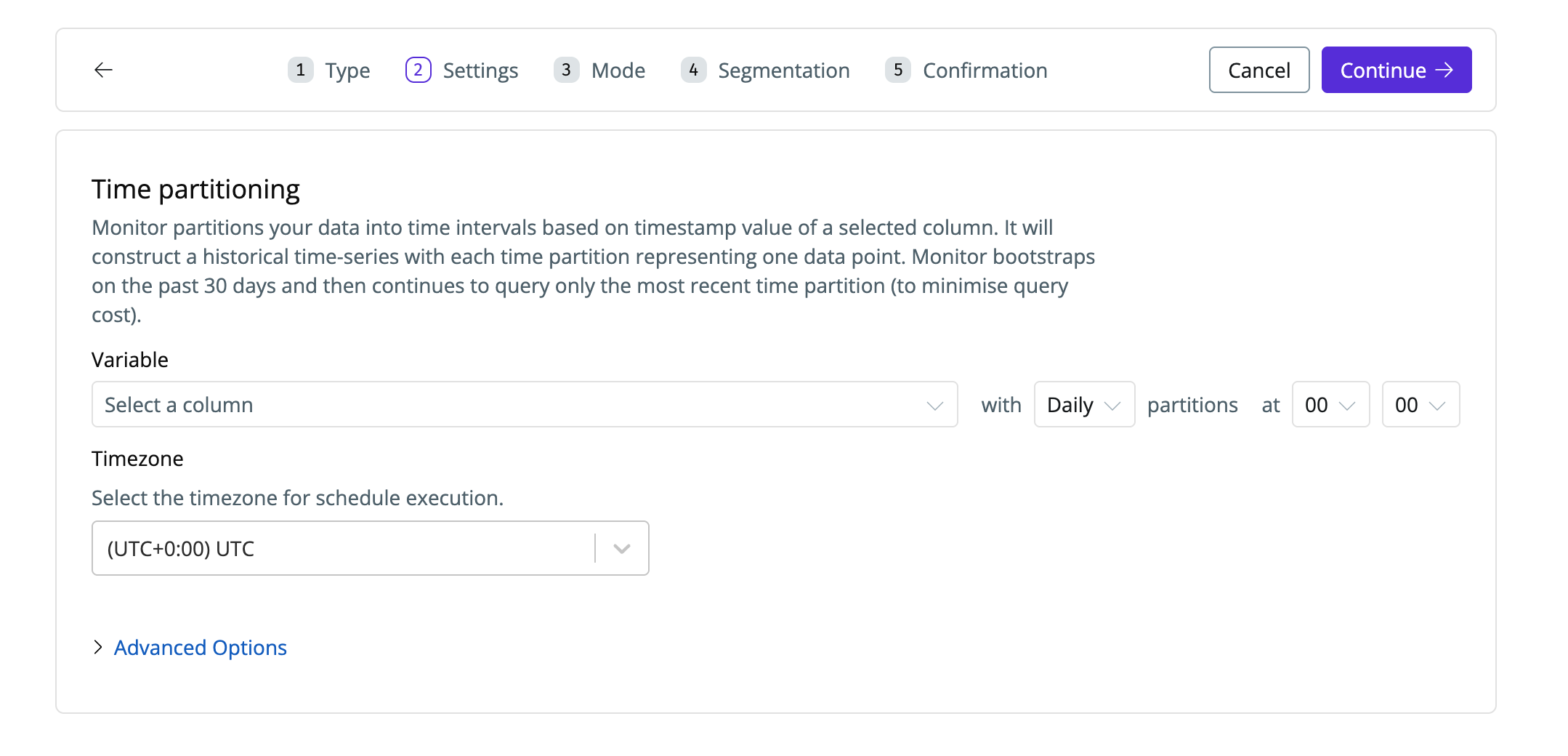
-
Set sensitivity, and severity (optional)
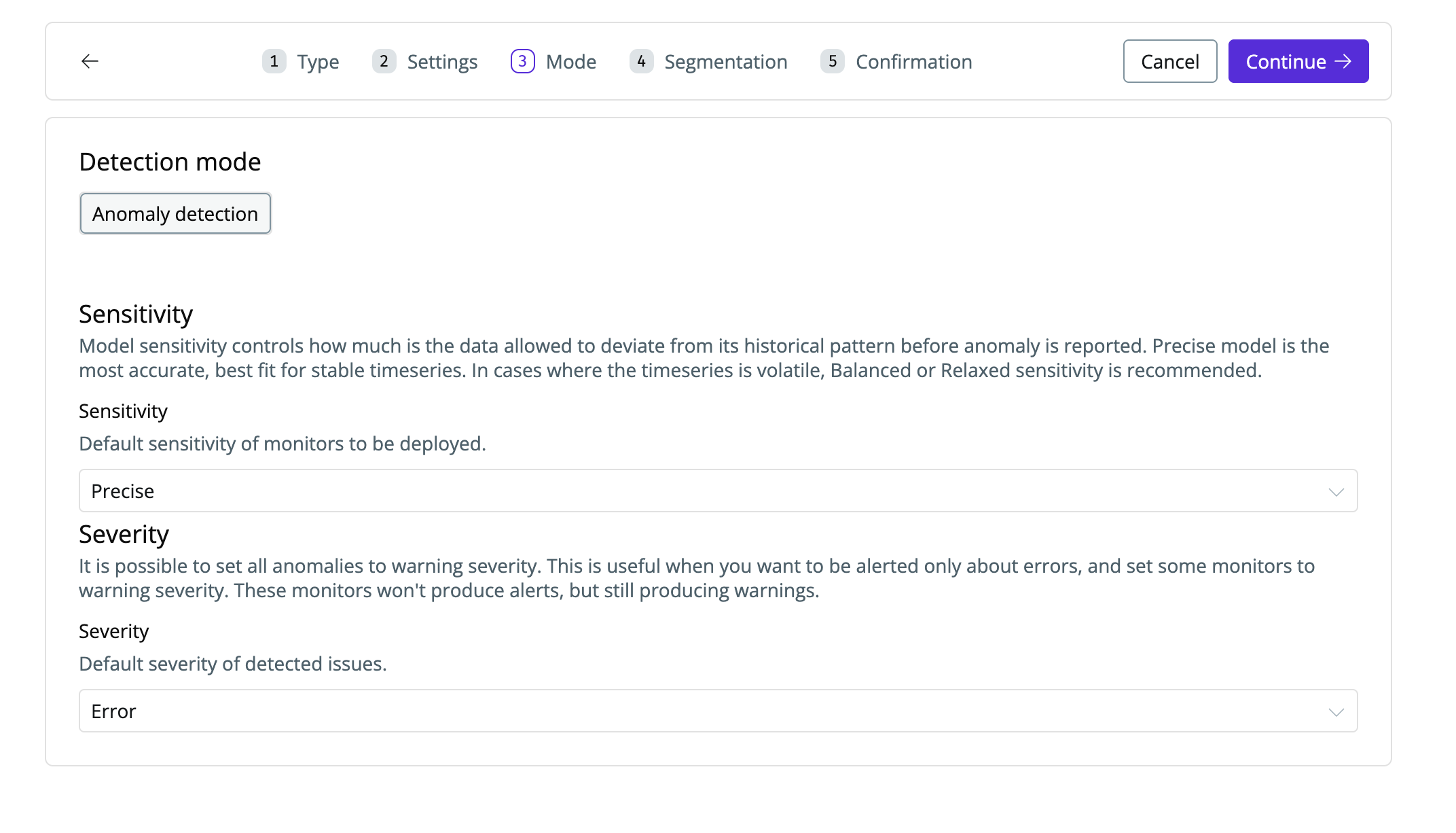
Field stats monitors bootstrap the past 30 days of history, then only query new partitions going forward to reduce cost. Anomaly detection begins immediately after setup.
Resetting a monitor
If you modify historical data and want to re-learn the 30-day baseline, open the monitor, go toSettings, and click Reset monitor.
This action is not reversible — only reset if you are certain the historical values have changed.